
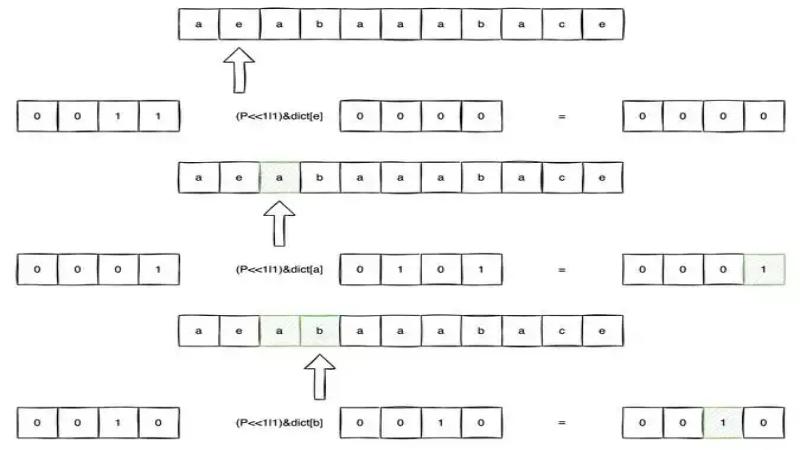
转载声明:文章来源https://blog.csdn.net/q7w8e9r4/article/details/132517206
1.朴素模式匹配算法(Naive String Matching Algorithm):也称为暴力匹配算法,通过逐个比较主串和模式串的字符来进行匹配。时间复杂度为O(m*n),其中m为主串的长度,n为模式串的长度。
2.KMP算法(Knuth-Morris-Pratt Algorithm):通过预处理模式串,构建部分匹配表(Partial Match Table),在匹配过程中根据部分匹配表进行跳跃式匹配,避免不必要的字符比较。时间复杂度为O(m+n),其中m为主串的长度,n为模式串的长度。
3.Boyer-Moore算法:通过预处理模式串,构建好后缀表(Good Suffix Table)和坏字符表(Bad Character Table),在匹配过程中根据好后缀表和坏字符表进行跳跃式匹配,提高匹配效率。时间复杂度为O(m*n),但在实际应用中通常比KMP算法更快。
Rabin-Karp算法:利用哈希函数计算主串中长度为模式串长度的子串的哈希值,并与模式串的哈希值进行比较,如果相等,则进一步比较子串和模式串的每个字符。时间复杂度为O((m-n+1)*n),其中m为主串的长度,n为模式串的长度。 这些算法在实际应用中有不同的优劣势,适用于不同的场景。可以根据具体需求和数据规模选择合适的字符串匹配算法。
以下是Java中几种字符串匹配算法的示例代码:
4.朴素模式匹配算法:
javaCopy codepublic class NaiveStringMatching {
public static void naiveMatch(String text, String pattern) {
int n = text.length();
int m = pattern.length();
for (int i = 0; i <= n - m; i++) {
int j;
for (j = 0; j < m; j++) {
if (text.charAt(i + j) != pattern.charAt(j))
break;
}
if (j == m)
System.out.println("Pattern found at index " + i);
}
}
public static void main(String[] args) {
String text = "ABABDABACDABABCABAB";
String pattern = "ABABCABAB";
naiveMatch(text, pattern);
}
}KMP算法:
javaCopy codepublic class KMPStringMatching {
public static void kmpMatch(String text, String pattern) {
int n = text.length();
int m = pattern.length();
int[] lps = computeLPSArray(pattern);
int i = 0, j = 0;
while (i < n) {
if (text.charAt(i) == pattern.charAt(j)) {
i++;
j++;
}
if (j == m) {
System.out.println("Pattern found at index " + (i - j));
j = lps[j - 1];
} else if (i < n && text.charAt(i) != pattern.charAt(j)) {
if (j != 0)
j = lps[j - 1];
else
i++;
}
}
}
private static int[] computeLPSArray(String pattern) {
int m = pattern.length();
int[] lps = new int[m];
int len = 0;
int i = 1;
while (i < m) {
if (pattern.charAt(i) == pattern.charAt(len)) {
len++;
lps[i] = len;
i++;
} else {
if (len != 0) {
len = lps[len - 1];
} else {
lps[i] = 0;
i++;
}
}
}
return lps;
}
public static void main(String[] args) {
String text = "ABABDABACDABABCABAB";
String pattern = "ABABCABAB";
kmpMatch(text, pattern);
}
}Boyer-Moore算法:
javaCopy codepublic class BoyerMooreStringMatching {
private static final int NO_OF_CHARS = 256;
public static void boyerMooreMatch(String text, String pattern) {
int n = text.length();
int m = pattern.length();
int[] badChar = new int[NO_OF_CHARS];
badCharHeuristic(pattern, m, badChar);
int s = 0;
while (s <= (n - m)) {
int j = m - 1;
while (j >= 0 && pattern.charAt(j) == text.charAt(s + j))
j--;
if (j < 0) {
System.out.println("Pattern found at index " + s);
if (s + m < n)
s += m - badChar[text.charAt(s + m)];
else
s += 1;
} else {
s += Math.max(1, j - badChar[text.charAt(s + j)]);
}
}
}
private static void badCharHeuristic(String pattern, int m, int[] badChar) {
for (int i = 0; i < NO_OF_CHARS; i++)
badChar[i] = -1;
for (int i = 0; i < m; i++)
badChar[pattern.charAt(i)] = i;
}
public static void main(String[] args) {
String text = "ABABDABACDABABCABAB";
String pattern = "ABABCABAB";
boyerMooreMatch(text, pattern);
}
}Java中字符串匹配算法
字符串匹配是计算机科学中常见的问题,它涉及在一个文本字符串中查找特定模式的出现位置。在Java中,有多种字符串匹配算法可供选择,每种算法都有其特点和适用场景。
1. Brute-Force算法
Brute-Force算法,也称为朴素匹配算法,是一种最简单直接的字符串匹配方法。它的原理是从文本字符串的第一个字符开始,逐个与模式字符串的字符进行比较,如果匹配失败,则将模式字符串向右移动一位,直到找到匹配或者遍历完整个文本字符串。 Brute-Force算法的时间复杂度为O(n*m),其中n是文本字符串的长度,m是模式字符串的长度。由于其简单直接的实现方式,Brute-Force算法在处理小规模字符串匹配问题时是有效的。
2. KMP算法
KMP算法是一种高效的字符串匹配算法,它利用了模式字符串中的部分匹配信息。该算法通过预处理模式字符串,构建一个部分匹配表(Partial Match Table),并利用该表在文本字符串中跳过已经匹配的部分。 KMP算法的时间复杂度为O(n+m),其中n是文本字符串的长度,m是模式字符串的长度。相比于Brute-Force算法,KMP算法可以在较短的时间内找到匹配位置,尤其在处理大规模文本字符串时表现出色。
3. Boyer-Moore算法
Boyer-Moore算法是一种高效的字符串匹配算法,它利用了模式字符串的最后一个字符在不匹配时的信息。该算法从文本字符串的末尾开始匹配,通过跳过不匹配的字符进行快速定位。 Boyer-Moore算法的时间复杂度为O(n+m),其中n是文本字符串的长度,m是模式字符串的长度。相比于KMP算法,Boyer-Moore算法在某些情况下能够更快地找到匹配位置。
4. Rabin-Karp算法
Rabin-Karp算法是一种基于哈希函数的字符串匹配算法。该算法通过计算模式字符串和文本字符串的哈希值,比较哈希值是否相等来判断是否匹配。在哈希值相等的情况下,再逐个比较字符确定匹配位置。 Rabin-Karp算法的时间复杂度为O(n+m),其中n是文本字符串的长度,m是模式字符串的长度。由于使用了哈希函数,Rabin-Karp算法在处理大规模字符串匹配问题时具有一定的优势。
5. 正则表达式
在Java中,使用正则表达式也是一种常见的字符串匹配方法。通过编写匹配规则,可以使用正则表达式的方法进行模式匹配和提取。 Java中提供了java.util.regex包,其中的Pattern和Matcher类可以用于处理正则表达式。使用正则表达式进行字符串匹配可以更加灵活,适用于复杂的字符串匹配需求。
结论
在Java中,有多种字符串匹配算法可供选择,每种算法都有其适用的场景。根据实际需求和数据规模的不同,选择合适的字符串匹配算法可以提高程序的执行效率和性能。 无论选择哪种算法,理解其原理和实现方式是非常重要的。通过合理选择和使用字符串匹配算法,可以更好地解决实际问题,并提升程序的运行效率。


帖子还没人回复快来抢沙发