

转载声明:文章来源:https://blog.csdn.net/weixin_34910922/article/details/118228250
1、基于滑动窗口的目标检测算法
首先固定一个于滑动窗口区域,然后将滑动窗口在图像上按照指定步长进行滑动,对于每一的滑动得到区域进行预测,判断该区域中存在目标的概率。
调整滑动窗口的大小、滑动步长,继续以同样的方式滑动,预测。
滑动窗口目标检测算法也有很明显的缺点,就是计算成本,因为你在图片中剪切出太小方块,卷积网络要一个个地处理。如果你选用的步幅很大,显然会减少输入卷积网络的窗口个数,但是粗糙间隔尺寸可能会影响性能。反之,如果采用小粒度或小步幅,传递给卷积网络的小窗口会特别多,这意味着超高的计算成本。
另外,滑动窗本身窗口大小大部分情况下并不完全贴合目标尺度;一张图滑动窗预测后,会输出多个结果,需对输出结果做NMS(非极大值抑制),再作为最终输出结果。
2、卷积的滑动窗口实现
构建滑动窗口的卷积应用,首先要知道如何把神经网络的全连接层转化成卷积层。具体做法:使用1*1卷积替换全连接层。
假设对象检测算法输入一个14×14×3的图像,输出为4类别(可以是行人、汽车、摩托车和背景或其它对象)的y。我们使用卷积层对全连接层进行替换。
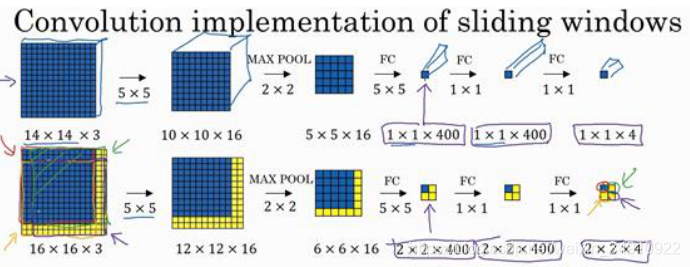
为什么需要使用卷积层对全连接层进行替换?
1、全连接层打破了卷积后的feature map位置映射关系;
2、全连接层的运算量非常大,使用卷积操作进行替换,提升速度。
使用400个5×5×16卷积替换第一个FC层,使用400个1×1×400卷积替换第二个FC层,最后经由1×1过滤器的处理,得到一个softmax激活值,通过卷积网络,我们最终得到这个1×1×4的输出层,而不是这4个数字。
经典部分:
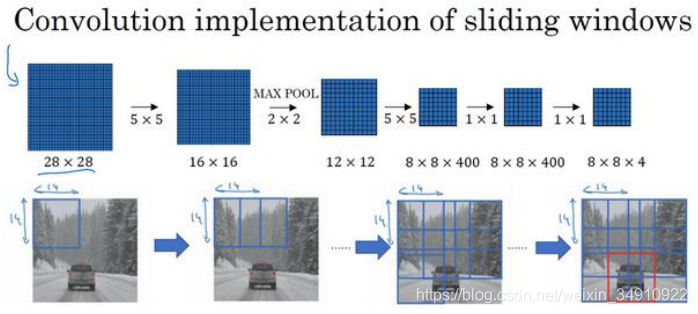
假设输入给卷积网络的图片大小是 14×14×3,测试集图片是 16×16×3,现在给这个输入图片加上黄色条块,在最初的滑动窗口算法中,你会把这片蓝色区域输入卷积网络(红色笔标记)生成 0 或 1 分类。接着滑动窗口,步幅为 2 个像素,向右滑动 2 个像素,将这个绿框区域输入给卷积网络,运行整个卷积网络,得到另外一个标签 0 或 1。继续将这个橘色区域输入给卷积网络,卷积后得到另一个标签,最后对右下方的紫色区域进行最后一次卷积操作。
我们在这个 16×16×3 的小图像上滑动窗口,卷积网络运行了 4 次,于是输出了了 4 个标签。
结果发现,这 4 次卷积操作中很多计算都是重复的。所以执行滑动窗口的卷积时使得卷积网络在这 4 次前向传播过程中共享很多计算,最终得到2×2×4 的输出层。
最终,在输出层这 4 个子方块中,蓝色的是图像左上部分14×14 的输出(红色箭头标识),右上角方块是图像右上部分(绿色箭头标识)的对应输出,左下角方块是输入层左下角(橘色箭头标识),也就是这个 14×14 区域经过卷积网络处理后的结果,同样,右下角这个方块是卷积网络处理输入层右下角 14×14 区域(紫色箭头标识)的结果。
结论:
卷积操作的原理是我们不需要把输入图像分割成四个子集,分别执行前向传播, 而是把它们作为一张图片输入给卷积网络进行计算,其中的公共区域可以共享很多计算,就像这里我们看到的这个 4 个 14×14 的方块一样。
同样,假如对一个 28×28×3 的图片应用滑动窗口操作,如果以同样的方式运行前向传播,最后得到 8×8×4 的结果。跟上一个范例一样,以 14×14 区域滑动窗口,首先在这个区域应用滑动窗口,其结果对应输出层的左上角部分。接着以大小为2 的步幅不断地向右移动窗口,直到第 8 个单元格,得到输出层的第一行。然后向图片下方移动,最终输出这个 8×8×4 的结果。因为最大池化参数为 2,相当于以大小为 2 的步幅在原始图片上应用神经网络。
总结一下滑动窗口的实现过程,在图片上剪切出一块区域,假设它的大小是 14×14,把它输入到卷积网络。继续输入下一块区域,大小同样是 14×14,重复操作,直到某个区域识别到汽车。
但是正如在前一页所看到的,我们不能依靠连续的卷积操作来识别图片中的汽车,比如,我们可以对大小为 28×28 的整张图片进行卷积操作,一次得到所有预测值,如果足够幸运,神经网络便可以识别出汽车的位置。
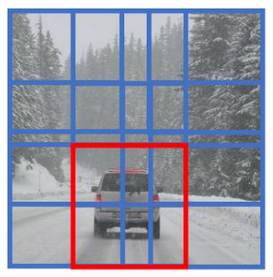
以上就是在卷积层上应用滑动窗口算法的内容,它提高了整个算法的效率。不过这种算法仍然存在一个缺点,就是边界框的位置可能不够准确。下节课,我们将学习如何解决这个问题。
在训练阶段的输入是14×14×3的输入图像,然后经过一系列的卷积运算,得到1×1×4的输出。对于检测阶段,在这个16×16×3的小图像上滑动窗口,卷积网络运行了4次,于是输出了了4个标签。该卷积操作的原理是我们不需要把输入图像分割成四个子集,分别执行前向传播,而是把它们作为一张图片输入给卷积网络进行计算,其中的公共区域可以共享很多计算,就像这里我们看到的这个4个14×14的方块一样。




帖子还没人回复快来抢沙发