
转载声明:原文链接:https://blog.csdn.net/wtyicy/article/details/115922106
1、IO分类
针对操作对象的大致分类
磁盘I/O
网络I/O
内存映射I/O
Direct I/O
数据库I/O
Java相关分类
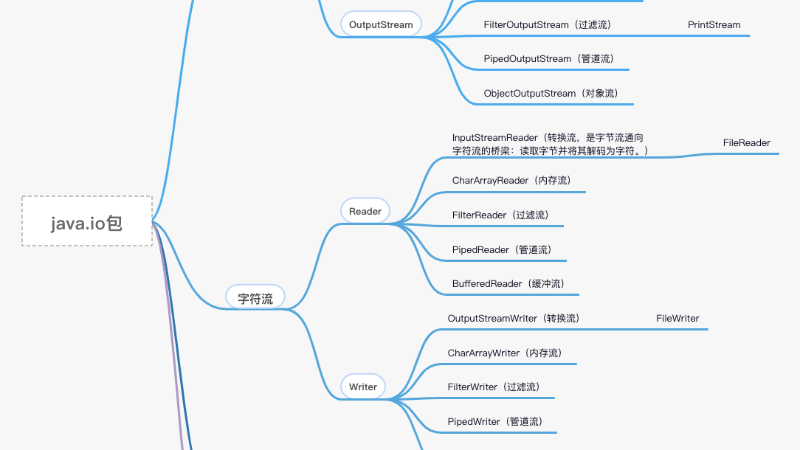
基于字节操作的InputStream/OutputStream
基于字符操作的Writer/Reader
基于磁盘的文件I/O
基于网络的Socket-I/O
阻塞与同步分类
BIO(同步&阻塞)
NIO(同步&非阻塞)
AIO(异步)
2、IO里面的常见类,字节流、字符流、接口、实现类、方法阻塞?
输入流就是从外部文件输入到内存,输出流主要是从内存输出到文件。
IO里面常见的类,第一印象就只知道IO流中有很多类,IO流主要分为字符流和字节流。字符流中有抽象类InputStream和OutputStream,它们的子类FileInputStream,FileOutputStream,BufferedOutputStream等。字符流BufferedReader和Writer等。都实现了Closeable, Flushable, Appendable这些接口。程序中的输入输出都是以流的形式保存的,流中保存的实际上全都是字节文件。
java中的阻塞式方法是指在程序调用改方法时,必须等待输入数据可用或者检测到输入结束或者抛出异常,否则程序会一直停留在该语句上,不会执行下面的语句。比如read()和readLine()方法。
3、select、poll、epoll工作原理
select、poll、epoll 都是 I/O 多路复用的机制。I/O 多路复用可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或者写就绪),能够通知程序进行相应的读写操作。但select、poll、epoll 本质上都是同步 I/O ,因为他们都需要在读写事件就绪后自己负责进行读写,也就是说这个读写过程是阻塞的,而异步 I/O 则无需自己负责进行读写,异步 I/O 的实现会负责把数据从内核拷贝到用户空间。
3.1、select
首先创建事件的描述符集合。对于一个描述符,可以关注其上的读事件、写事件以及异常事件,所以要创建三类事件的描述符集合,分别用来收集读事件描述符、写事件描述符以及异常事件描述符。select 调用时,首先将时间描述符集合 fd_set 从用户空间拷贝到内核空间;注册回调函数并遍历所有 fd ,调用其 poll 方法, poll 方法返回时会返回一个描述读写操作是否就绪的 mask 掩码,根据这个掩码给 fd 赋值,如果遍历完所有 fd 后依旧没有一个可以读写就绪的 mask 掩码,则会使进程睡眠;如果已过超时时间还是未被唤醒,则调用 select 的进程会被唤醒并获得 CPU ,重新遍历 fd 判断是否有就绪的fd;最后将 fd_set从内核空间拷贝回用户空间。
select缺点:
每次调用 select ,都需要把 fd 集合从用户态拷贝到内核态,这个开销在 fd 很多时会很大
同时每次调用 select 都需要在内核遍历传递进来的所有 fd ,这个开销在 fd 很多时也很大
select支持的文件描述符数量较小,默认是1024
伪代码:
struct timeval tv = {.tv_sec = 1, .tv_usec = 0};
ssize_t nbytes;
while(1) {
FD_ZERO(&read_fds);
setnonblocking(fd1);
setnonblocking(fd2);
FD_SET(fd1, &read_fds);
FD_SET(fd2, &read_fds);
// 把要监听的fd拼到一个数组里,而且每次循环都得重来一次...
if (select(FD_SETSIZE, &read_fds, NULL, NULL, &tv) < 0) { // block住,直到有事件到达
perror("select出错了");
exit(EXIT_FAILURE);
}
for (int i = 0; i < FD_SETSIZE; i++) {
if (FD_ISSET(i, &read_fds)) {
/* 检测到第[i]个读取fd已经收到了,这里假设buf总是大于到达的数据,所以可以一次read完 */
if ((nbytes = read(i, buf, sizeof(buf))) >= 0) {
process_data(nbytes, buf);
} else {
perror("读取出错了");
exit(EXIT_FAILURE);
}
}
}
}3.2、poll
poll 是 select 的优化版。poll 使用 pollfd 结构而不是 select 的 fd_set 结构。select 需要为读事件、写事件和异常事件分别创建一个描述符集合,轮询时需要分别轮询这三个集合。而 poll 库只需要创建一个集合,在每个描述符对应的结构上分别设置读事件、写事件或者异常事件,最后轮询时可同时检查这三类事件是否发生。
3.3、epoll
select 与 poll 中,都创建一个待处理事件列表。然后把这个列表发送给内核,返回的时候再去轮询这个列表,以判断事件是否发生。在描述符比较多的时候,效率极低。epoll 将文件描述符列表的管理交给内核负责,每次注册新的事件时,将 fd 拷贝仅内核,epoll 保证 fd 在整个过程中仅被拷贝一次,避免了反复拷贝重复 fd 的巨大开销。此外,一旦某个事件发生时,内核就把发生事件的描述符列表通知进程,避免对所有描述符列表进行轮询。最后, epoll 没有文件描述符的限制,fd 上限是系统可以打开的最大文件数量,通常远远大于2048 。
伪代码:
#define MAX_EVENTS 10
struct epoll_event ev, events[MAX_EVENTS];
int nfds, epfd, fd1, fd2;
// 假设这里有两个socket,fd1和fd2,被初始化好。
// 设置为non blocking
setnonblocking(fd1);
setnonblocking(fd2);
// 创建epoll
epfd = epoll_create(MAX_EVENTS);
if (epollfd == -1) {
perror("epoll_create1");
exit(EXIT_FAILURE);
}
//注册事件
ev.events = EPOLLIN | EPOLLET;
ev.data.fd = fd1;
if (epoll_ctl(epollfd, EPOLL_CTL_ADD, fd1, &ev) == -1) {
perror("epoll_ctl: error register fd1");
exit(EXIT_FAILURE);
}
if (epoll_ctl(epollfd, EPOLL_CTL_ADD, fd2, &ev) == -1) {
perror("epoll_ctl: error register fd2");
exit(EXIT_FAILURE);
}
// 监听事件
for (;;) {
nfds = epoll_wait(epdf, events, MAX_EVENTS, -1);
if (nfds == -1) {
perror("epoll_wait");
exit(EXIT_FAILURE);
}
for (n = 0; n < nfds; ++n) { // 处理所有发生IO事件的fd
process_event(events[n].data.fd);
// 如果有必要,可以利用epoll_ctl继续对本fd注册下一次监听,然后重新epoll_wait
}
}3.4、select、poll、epoll对比
select,poll实现需要自己不断轮询所有 fd 集合,直到设备就绪,期间可能要睡眠和唤醒多次交替。而 epoll 其实也需要调用 epoll_wait 不断轮询就绪链表,期间也可能多次睡眠和唤醒交替。但是它在设备就绪时,调用回调函数,把就绪 fd 放入就绪链表中,并唤醒在 epoll_wait 中进入睡眠的进程。虽然都要睡眠和交替,但是 select 和 poll 在醒着的时候要遍历整个 fd 集合,而 epoll 在醒着的时候只要判断一下就绪链表是否为空就行了,这节省了大量的 CPU 时间。
3.5、select、poll、epoll各自的应用场景
select:timeout 参数精度为 1ns,而 poll 和 epoll 为 1ms,因此 select 更加适用于实时性要求比较高的场景,比如核反应堆的控制。select 可移植性更好,几乎被所有主流平台所支持。
poll:poll 没有最大描述符数量的限制,如果平台支持并且对实时性要求不高,应该使用 poll 而不是 select
epoll:只运行在 Linux 平台上,有大量的描述符需要同时轮询,并且这些连接最好是长连接;需要同时监控小于 1000 个描述符,就没有必要使用 epoll,因为这个应用场景下并不能体现 epoll 的优势;需要监控的描述符状态变化多,而且都是非常短暂的,也没有必要使用 epoll。因为 epoll 中的所有描述符都存储在内核中,造成每次需要对描述符的状态改变都需要通过 epoll_ctl() 进行系统调用,频繁系统调用降低效率。并且 epoll 的描述符存储在内核,不容易调试
4、BIO、NIO、AIO工作原理
4.1、BIO
BIO 全称 Block-IO 是一种同步阻塞的通信模式。BIO 是一种比较传统的通信方式,模式简单,使用方便。但并发处理能力低,通信耗时,依赖网速。服务器通过一个 Acceptor 线程负责监听客户端请求和为每个客户端创建一个新的线程进行链路处理。典型的请求一应答模式。若客户端数量增多,频繁地创建和销毁线程会给服务器打开很大的压力。后改良为用线程池的方式代替新增线程,被称为伪异步IO。BIO 模型中通过 Socket 和 ServerSocket 完成套接字通道的实现。BIO 具有阻塞性,同步性。
4.2、NIO
NIO 全称 New IO,也叫 Non-Block IO 是一种非阻塞同步的通信模式。NIO 相对于 BIO 来说一大进步。客户端和服务器之间通过 Channel 通信。NIO 可以在 Channel 进行读写操作。这些 Channel 都会被注册在 Selector 多路复用器上。Selector 通过一个线程不停的轮询这些 Channel 。找出已经准备就绪的 Channel 执行 IO 操作。NIO 通过一个线程轮询,实现千万个客户端的请求,这就是非阻塞 NIO 的特点。NIO 的特性如下:
缓冲区Buffer:它是 NIO 与 BIO 的一个重要区别。BIO 是将数据直接写入或读取到 Stream 对象中。而 NIO 的数据操作都是在缓冲区中进行的。缓冲区实际上是一个数组。 Buffer 最常见的类型是 ByteBuffer ,另外还有 CharBuffer , ShortBuffer , IntBuffer , LongBuffer , FloatBuffer , DoubleBuffer
通道Channel:和流不同,通道是双向的。NIO 可以通过 Channel 进行数据的读,写和同时读写操作(全双工?)。通道分为两大类:一类是网络读写,一类是用于文件操作
多路复用器Selector:NIO 编程的基础。多路复用器提供选择已经就绪的任务的能力。就是 Selector 会不断地轮询注册在其上的通道(Channel),如果某个通道处于就绪状态,会被 Selector 轮询出来,然后通过 SelectionKey 可以取得就绪的 Channel 集合,从而进行后续的 IO 操作。服务器端只要提供一个线程负责 Selector 的轮询,就可以接入成千上万个客户端,这就是JDK NIO库的巨大进步
NIO 模型中通过 SocketChannel 和 ServerSocketChannel 完成套接字通道的实现。非阻塞/阻塞,同步,避免TCP建立连接使用三次握手带来的开销
伪代码:
struct timespec sleep_interval{.tv_sec = 0, .tv_nsec = 1000};
ssize_t nbytes;
while (1) {
/* 尝试读取 */
if ((nbytes = read(fd, buf, sizeof(buf))) < 0) {
if (errno == EAGAIN) { // 没数据到
perror("nothing can be read");
} else {
perror("fatal error");
exit(EXIT_FAILURE);
}
} else { // 有数据
process_data(buf, nbytes);
}
// 处理其他事情,做完了就等一会,再尝试
nanosleep(sleep_interval, NULL);
}4.3、AIO
AIO 也叫 NIO2.0 是一种非阻塞异步的通信模式。在 NIO 的基础上引入了新的异步通道的概念,并提供了异步文件通道和异步套接字通道的实现。AIO 并没有采用 NIO 的多路复用器,而是使用异步通道的概念。其 read, write 方法的返回类型都是 Future 对象。而 Future 模型是异步的。AIO 模型中通过 AsynchronousSocketChannel 和AsynchronousServerSocketChannel 完成套接字通道的实现。AIO 具有非阻塞性和异步性。
从编程模式上来看 AIO 相对于 NIO 的区别在于,NIO 需要使用者线程不停的轮询 IO 对象,来确定是否有数据准备好可以读了。而 AIO 则是在数据准备好之后,才会通知数据使用者,这样使用者就不需要不停地轮询了。当然 AIO 的异步特性并不是 Java 实现的伪异步,而是使用了系统底层 API 的支持。在 Unix 系统下,采用了epoll IO 模型,而 windows 便是使用了 IOCP 模型。
4.4、BIO vs NIO
BIO是面向流(字节流和字符流)操作的,而NIO是面向缓冲区操作的
BIO是阻塞性IO,而NIO是非阻塞性IO
BIO不支持选择器,而NIO支持选择器
同步阻塞IO : 用户进程发起一个 IO 操作以后,必须等待 IO 操作的真正完成后,才能继续运行
同步非阻塞IO: 用户进程发起一个 IO 操作以后可做其它事情,但用户进程需要经常询问 IO 操作是否完成,这样造成不必要的 CPU 资源浪费
异步非阻塞IO: 用户进程发起一个 IO 操作然后立即返回,等 IO 操作真正的完成以后,应用程序会得到 IO 操作完成的通知
4.5、AIO vs NIO
NIO 需要使用者线程不停地轮训 IO 对象,来确定是否有数据准备好并可读
AIO 在数据准备好后通知使用者,避免了使用者的不断轮训


帖子还没人回复快来抢沙发