

转载声明:文章来源 https://blog.csdn.net/edogawachia/article/details/79357844
随机森林(Random Forest)算法原理
集成学习(Ensemble)思想、自助法(bootstrap)与bagging
**集成学习(ensemble)**思想是为了解决单个模型或者某一组参数的模型所固有的缺陷,从而整合起更多的模型,取长补短,避免局限性。
随机森林就是集成学习思想下的产物,将许多棵决策树整合成森林,并合起来用来预测最终结果。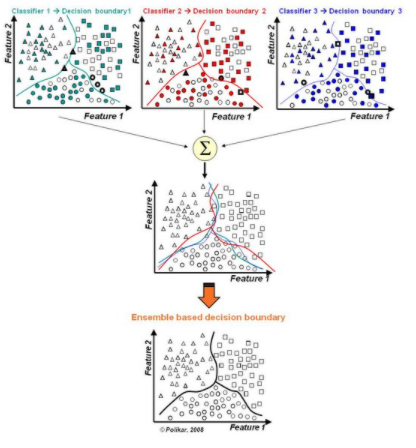
首先,介绍自助法(bootstrap),这个奇怪的名字来源于文学作品 The Adventures of Baron Munchausen(吹牛大王历险记),这个作品中的一个角色用提着自己鞋带的方法把自己从湖底下提了上来。
因此采用意译的方式,叫做自助法。
自助法顾名思义,是这样一种方法:
即从样本自身中再生成很多可用的同等规模的新样本,从自己中产生和自己类似的,所以叫做自助,即不借助其他样本数据。
自助法的具体含义如下:
如果我们有个大小为N的样本,我们希望从中得到m个大小为N的样本用来训练。
那么我们可以这样做:
首先,在N个样本里随机抽出一个样本x1,然后记下来,放回去,再抽出一个x2,… ,这样重复N次,即可得到N的新样本,这个新样本里可能有重复的。重复m次,就得到了m个这样的样本。实际上就是一个有放回的随机抽样问题。
每一个样本在每一次抽的时候有同样的概率(1/N)被抽中。
这个方法在样本比较小的时候很有用,比如我们的样本很小,但是我们希望留出一部分用来做验证,那如果传统方法做train-validation的分割的话,样本就更小了,bias会更大,这是不希望的。
而自助法不会降低训练样本的规模,又能留出验证集(因为训练集有重复的,但是这种重复又是随机的),因此有一定的优势。
至于自助法能留出多少验证,或者说,m个样本的每个新样本里比原来的样本少了多少?
可以这样计算:每抽一次,任何一个样本没抽中的概率为 (1-1/N),一共抽了N次,所以任何一个样本没进入新样本的概率为(1-1/N)N。
那么从统计意义上来说,就意味着大概有(1-1/N)N这么大比例的样本作为验证集。
当N→inf时,这个值大概是1/e,36.8%。
以这些为验证集的方式叫做包外估计(out of bag estimate)
bagging的名称来源于 ( Bootstrap AGGregatING ),意思是自助抽样集成,这种方法将训练集分成m个新的训练集,然后在每个新训练集上构建一个模型,各自不相干,最后预测时我们将这个m个模型的结果进行整合,得到最终结果。
整合方式就是:分类问题用majority voting,回归用均值。

bagging和boosting是集成学习两大阵营,之后在总结两者的异同。
决策树(Decision Tree)与随机森林(Random Forest)
决策树是用树的结构来构建分类模型,每个节点代表着一个属性,根据这个属性的划分,进入这个节点的儿子节点,直至叶子节点,每个叶子节点都表征着一定的类别,从而达到分类的目的。
常用的决策树有ID4,C4.5,CART等。在生成树的过程中,需要选择用那个特征进行剖分,一般来说,选取的原则是,分开后能尽可能地提升纯度,可以用信息增益,增益率,以及基尼系数等指标来衡量。如果是一棵树的话,为了避免过拟合,还要进行剪枝(prunning),取消那些可能会导致验证集误差上升的节点。
随机森林实际上是一种特殊的bagging方法,它将决策树用作bagging中的模型。
首先,用bootstrap方法生成m个训练集,然后,对于每个训练集,构造一颗决策树,在节点找特征进行分裂的时候,并不是对所有特征找到能使得指标(如信息增益)最大的,而是在特征中随机抽取一部分特征,在抽到的特征中间找到最优解,应用于节点,进行分裂。
随机森林的方法由于有了bagging,也就是集成的思想在,实际上相当于对于样本和特征都进行了采样(如果把训练数据看成矩阵,就像实际中常见的那样,那么就是一个行和列都进行采样的过程),所以可以避免过拟合。
prediction阶段的方法就是bagging的策略,分类投票,回归均值。




面试官逮着我问内存溢出和内存泄露,k8s,测试前置,jekins集群的问题