
转载声明:文章来源 https://blog.csdn.net/chndata/article/details/43792363
字符串模式匹配算法
(string searching/matchingalgorithms)
顾名思义,就是在一个文本或者较长的一段字符串中,找出一个或多个指定字符串(Pattern),并返回其位置。这类算法属基础算法,各种编程语言都将其包括在自带的String类函数中,而且由之衍生出来的正则表达式也是必须掌握的一种概念和编程技术。
Brute-Force算法
其思路很简单:从目标字符串初始位置开始,依次分别与Pattern的各个位置的字符比较。
如相同,比较下一个位置的字符直至完全匹配;如果不同则跳到目标字符串下一位置继续如此与Pattern比较,直至找到匹配字符串并返回其位置。
我们注意到Brute Force 算法是每次移动一个单位,一个一个单位移动显然太慢,设目标串String的长度为m,Pattern的长度为n,不难得出BF算法的时间复杂度最坏为O(mn),效率很低。
代码也很简单,如下所示(Java)。
不过,下面的代码有优化,例如21行的总的循环次数是 m – n, 33行的不匹配循环终止,都让时间复杂度大为降低。
/**
* Brute-Force算法
*
* @author stecai
*/
public class BruteForce {
/**
* 找出指定字符串在目标字符串中的位置
*
* @param source 目标字符串
* @param pattern 指定字符串
* @return 指定字符串在目标字符串中的位置
*/
public static int match(String source, String pattern) {
int index = -1;
boolean match = true;
for (int i = 0, len = source.length() - pattern.length(); i <= len; i++) {
match = true;
for (int j = 0; j < pattern.length(); j++) {
if (source.charAt(i + j) != pattern.charAt(j)) {
match = false;
break;
}
}
if (match) {
index = i;
break;
}
}
return index;
}
}KMP算法
KMP算法是一种改进的字符串匹配算法,关键是利用匹配失败后的信息,尽量减少模式串与主串的匹配次数以达到快速匹配的目的。
在BF算法的基础上使用next函数来找出下一次目标函数与Pattern比较的位置,因为BF算法每次移动一位的比较是冗余的,KMP利用Pattern字符重复的特性来排除不必要的比较,从而可以每次移动n位来排除冗余。
对于Next函数近似接近O(m),KMP算法的时间复杂度为O(n),所以整个算法的时间复杂度为O(n+m)。
例如:模式pattern,文本string。
Pattern: ABCAC
String: ABCADCACBAB
在红色字体处发生失配,按照传统算法,应当从第二个字符 B 对齐再进行匹配,这个过程中,对字符串String的访问发生了“回朔”。
我们不希望发生这样的回朔,而是试图通过尽可能的“向右滑动”模式串next数组对应位置的值,让Pattern中B字符对齐到String中D的字。
Pattern: ABCAC
String: ABCADCACBAB
因此,问题的关键是计算向右引动的串的模式值next[]。模式串开始为值(既next[0])为-1,后面的任一位置例如j,计算j之前(既0 ~ j-1)中最大的相同的前后缀的字符数量,即为next数组j位置的值。
例如:
位置 j | 0 | 1 | 2 | 3 | 4 | 5 |
模式串 | A | B | C | A | B | D |
next[] | -1 | 0 | 0 | 0 | 1 | 2 |
从上表可以看出, 3位置之前,前缀和后缀没有相同的,所以值为0;4位置之前有最大前后缀A,长度为1,所以值为1,5之前有最大前后缀AB,长度为2,所以值为2。
KMP虽然经典,很不容易理解,即使理解好了,编码也相当麻烦!特别是计算next数组的部分。
代码如下所示,核心是next[]数组的得出方法:
/**
* KMPSearch 算法
*
* @author stecai
*/
public class KMPSearch {
/**
* 获得字符串的next函数值
*
* @param str
* @return next函数值
*/
private static int[] calculateNext(String str) {
int i = -1;
int j = 0;
int length = str.length();
int next[] = new int[length];
next[0] = -1;
while (j < length - 1) {
if (i == -1 || str.charAt(i) == str.charAt(j)) {
i++;
j++;
next[j] = i;
} else {
i = next[i];
}
}
return next;
}
/**
* KMP匹配字符串
*
* @param source 目标字符串
* @param pattern 指定字符串
* @return 若匹配成功,返回下标,否则返回-1
*/
public static int match(String source, String pattern) {
int i = 0;
int j = 0;
int input_len = source.length();
int kw_len = pattern.length();
int[] next = calculateNext(pattern);
while ((i < input_len) && (j < kw_len)) {
// 如果j = -1,或者当前字符匹配成功(即S[i] == P[j]),都令i++,j++
if (j == -1 || source.charAt(i) == pattern.charAt(j)) {
j++;
i++;
} else {
// 如果j != -1,且当前字符匹配失败(即S[i] != P[j]),则令 i 不变,j = next[j],
// next[j]即为j所对应的next值
j = next[j];
}
}
if (j == kw_len) {
return i - kw_len;
} else {
return -1;
}
}
}Boyer-Moore算法
Boyer-Moore算法是一种基于后缀匹配的模式串匹配算法。
后缀匹配就是模式串从右到左开始比较,但模式串的移动还是从左到右的。
字符串匹配的关键就是模式串的如何移动才是最高效的。
BM的时间复杂度,最好O(n/m),最坏O(n),通常在longer pattern下BM表现更出色。(本文用的是坏字符原则,如不理解,请看参考链接文章)
例如:模式pattern,文本string。
Pattern: AT-THAT
String: WHICH-FINALLY-HATS.--AT-THAT-POINT...
左对齐pattern与string,位置(p)指向对齐后的右end,开始比对。
如果pattern [p]= string[p],那么往左移动(移到左start说明匹配上了),否则就要移动pattern进行重新对齐,重新对齐后,进行重新比对。
有两种情况:
末位不匹配,且string[p]在pattern中不存在,那么pattern可以一下子右移patlen个单位。
Pattern: AT-THAT
String: WHICH-FINALLY-HATS.--AT-THAT-POINT...
末位不匹配,但string[p]在pattern中存在。
例如上边T和-(如果有多个,那就找最靠右的那个),距离pattern右端为(patlen – 最右边那个Pattern[p]) 的位置。
Pattern: AT-THAT
String: WHICH-FINALLY-HATS.--AT-THAT-POINT...
部分匹配,下例绿色部分AT相同,但string[p]既A在pattern中存在2个位置,很显然如果我们用最右边的那个A既已经被匹配正确的,那么就会产生回退。因此我们应该用左边的那个,既匹配不成功位置之前最右边的那个。距离pattern右端为(patlen –既匹配不成功位置之前最右边的那个Pattern [p]) 的位置。
移动前
Pattern: AT-THAT
String: WHICH-FAATNALLY-HATS.--AT-THAT-POINT...
移动后
Pattern: AT-THAT
String: WHICH-FAATNALLY-HATS.--AT-THAT-POINT...
此为简化版的算法,事实上部分匹配还有更优化的最大右移量。在此就不做深入研究了。
代码如下所示(Java):
/**
* Boyer-Moore算法
*
* @author stecai
*/
public class BoyerMoore {
/**
* 计算滑动距离
*
* @param c 主串(源串)中的字符
* @param T 模式串(目标串)字符数组
* @param noMatchPos 上次不匹配的位置
* @return 滑动距离
*/
private static int dist(char c, char T[], int noMatchPos) {
int n = T.length;
for (int i = noMatchPos; i >= 1; i--) {
if (T[i - 1] == c) {
return n - i;
}
}
// c不出现在模式中时
return n;
}
/**
* 找出指定字符串在目标字符串中的位置
*
* @param source 目标字符串
* @param pattern 指定字符串
* @return 指定字符串在目标字符串中的位置
*/
public static int match(String source, String pattern) {
char[] s = source.toCharArray();
char[] t = pattern.toCharArray();
int slen = s.length;
int tlen = t.length;
if (slen < tlen) {
return -1;
}
int i = tlen;
int j = -1;
while (i <= slen) {
j = tlen;
// S[i-1]与T[j-1]若匹配,则进行下一组比较;反之离开循环。
while (j > 0 && s[i - 1] == t[j - 1]) {
i--;
j--;
}
// j=0时,表示完美匹配,返回其开始匹配的位置
if (0 == j) {
return i;
} else {
// 把主串和模式串均向右滑动一段距离dist(s[i-1]).
i = i + dist(s[i - 1], t, j - 1);
}
}
// 模式串与主串无法匹配
return -1;
}
}unday算法
Sunday算法的思想和BM算法中的坏字符思想非常类似。
差别只是在于Sunday算法在匹配失败之后,是取String串中当前和Pattern字符串对应的部分后面一个位置的字符来做坏字符匹配。
当发现匹配失败的时候就判断母串中当前偏移量+Pattern字符串长度 (假设为K位置)的字符在Pattern字符串中是否存在。
如果存在,则将该位置和Pattern字符串中的该字符对齐,再从头开始匹配;如果不存在,就将Pattern字符串向后移动,和母串k处的字符对齐,再进行匹配。重复上面的操作直到找到,或母串被找完结束。
该算法最坏情况下的时间复杂度为O(NM)。
对于短模式串的匹配问题,该算法执行速度较快。
例如:模式pattern,文本string。
Pattern: ATTHAT
String: AHICHTANALLY-HATS.--AT-THAT-POINT...
我们看到A-H没有对上,我们就看匹配串中的A 在模式串的位置
Pattern: ATTHAT
String: AHICHTANALLY-HATS.--AT-THAT-POINT...
如果模式串中的没有那个字符,跳过去。
Pattern: ATTHAT
String: AHICHTENALLY-HATS.--AT-THAT-POINT...
代码如下所示(Java):
import java.util.HashMap;
import java.util.Map;
/**
* Sunday算法
*
* @author stecai
*/
public class Sunday {
private static int currentPos = 0;
// 匹配字符的Map,记录改匹配字符串有哪些char并且每个char最后出现的位移
private static Map map = new HashMap();
// Sunday匹配时,用来存储Pattern中每个字符最后一次出现的位置,从右到左的顺序
public static void initMap(String pattern) {
for (int i = 0, plen = pattern.length(); i < plen; i++) {
map.put(pattern.charAt(i), i);
}
}
/**
* Sunday匹配,假定Text中的K字符的位置为:当前偏移量+Pattern字符串长度+1
*
* @param source 目标字符串
* @param pattern 指定字符串
* @return 指定字符串在目标字符串中的位置
*/
public static int match(String source, String pattern) {
int slen = source.length();
int plen = pattern.length();
// 当剩下的原串小于指定字符串时,匹配不成功
if ((slen - currentPos) < plen) {
return -1;
}
// 如果没有匹配成功
if (!isMatchFromPos(source, pattern, currentPos)) {
int nextStartPos = currentPos + plen;
// 如果移动位置正好是结尾,即是没有匹配到
if ((nextStartPos) == slen) {
return -1;
}
// 如果匹配的后一个字符没有在Pattern字符串中出现,则跳过整个Pattern字符串长度
if (!map.containsKey(source.charAt(nextStartPos))) {
currentPos = nextStartPos;
} else {
// 如果匹配的后一个字符在Pattern字符串中出现,则将该位置和Pattern字符串中的最右边相同字符的位置对齐
currentPos = nextStartPos - (Integer) map.get(source.charAt(nextStartPos));
}
return match(source, pattern); }
else {
return currentPos;
}
}
/**
* 检查从Text的指定偏移量开始的子串是否和Pattern匹配
*
* @param source 目标字符串
* @param pattern 指定字符串
* @param pos 起始位置
* @return 是否匹配
*/
private static boolean isMatchFromPos(String source, String pattern, int pos) {
for (int i = 0, plen = pattern.length(); i < plen; i++) {
if (source.charAt(pos + i) != pattern.charAt(i)) {
return false;
}
}
return true;
}
} 运行实例比较
如下实例:
String: ABA
Pattern: BAC
String: BBC ABCDABABCDABCDABDE
Pattern: ABCDABD
String: AAAAAAAAAAAAAAAAAAAAAAAAAAAAE
Pattern: AAAE
String: AAAAAAAAAAAAAAAAAAAAAAAAAAAAE
Pattern: CCCE
String: WHICH-FINALLY-HATS.--AT-THAT-POINT...
Pattern: AT-THAT
10000000次循环,时间为毫秒(ms)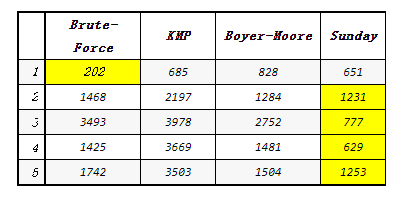
从上面的结果来看:
KMP, Boyer-Moore, Sunday相比较,很很明显的性能差异。既KMP < Boyer-Moore < Sunday.
KMP, Boyer-Moore, Sunday都有对pattern串的预处理,像KMP的next,Boyer-Moore的dist,以及Sunday的map生成,要耗费部分资源,在某些情况下,例如上面的1的情况(source和pattern长度差不是很大,及上面提到的没有达到最大的时间复杂度),Brute-Force能达到很好效果。是否能有好的性能,主要是看它移动的幅度消耗的性能是否能抵消对pattern串的预处理,个人建议,在Brute-Force和Sunday里面选一种。当然,仅现于以上四种算法的选择,可能有更优的算法。
参考:
http://en.wikipedia.org/wiki/String_searching_algorithm
http://blog.sina.com.cn/s/blog_4b241f500102v4l6.html
http://blog.csdn.net/iJuliet/article/details/4200771




非常详细,很有用
希望今年秋招能有所收获
学到数据库了 感觉有些难度 我太难了
太强了,学完框架再回来看
哇,好棒啊,崇拜的小眼神
又搞定一个知识盲区